LlamaIndex🦙 是一個強大的工具,可用於評估大型語言模型(LLM)的性能。評估和基準測試是 LLM 開發中的關鍵概念。要提高 LLM 應用程序(RAG、Agent)的性能,必須有一種方法來衡量其表現。LlamaIndex 提供了重要的模塊,幫助評估生成結果和檢索結果的品質。
LlamaIndex🦙 提供了基於LLM的評估模塊來衡量結果的品質,目前主流方法還是以更強大的 LLM 來對生成的結果評分,相對的這些方法在 API 的花費會提升。
忠誠度 Faithfulness: 生成的回答是否由提供的相關上下文而來,可以避免生成幻覺給使用者。概念是由 gpt-4 等較精準的 LLM 來當裁判,透過 Prompt Engineering 的方式來檢查,但相對的成本也較高。
from llama_index.core import VectorStoreIndex
from llama_index.llms.openai import OpenAI
from llama_index.core.evaluation import FaithfulnessEvaluator
# build index
...
# define evaluator
llm = OpenAI(model="gpt-4", temperature=0.0)
evaluator = FaithfulnessEvaluator(llm=llm)
# query index
query_engine = vector_index.as_query_engine()
response = query_engine.query(
"國立台灣美術館在哪裡?", similarity_top_k=2
)
eval_result = evaluator.evaluate_response(response=response)
print(str(eval_result.passing))
# OutPut[1]: True
【Prompt】
user: Please tell if a given piece of information is supported by the context.
You need to answer with either YES or NO.
Answer YES if any of the context supports the information, even if most of the context is unrelated. Some examples are provided below.
Information: Apple pie is generally double-crusted.
Context: An apple pie is a fruit pie in which the principal filling ingredient is apples.
Apple pie is often served with whipped cream, ice cream ('apple pie à la mode'), custard or cheddar cheese.
It is generally double-crusted, with pastry both above and below the filling; the upper crust may be solid or latticed (woven of crosswise strips).
Answer: YES
Information: Apple pies tastes bad.
Context: An apple pie is a fruit pie in which the principal filling ingredient is apples.
Apple pie is often served with whipped cream, ice cream ('apple pie à la mode'), custard or cheddar cheese.
It is generally double-crusted, with pastry both above and below the filling; the upper crust may be solid or latticed (woven of crosswise strips).
Answer: NO
Information: 台中
Context: 台北是台灣的首都,也是台灣政治、經濟、文化和交通的中心。這座城市充滿了活力與多元文化,結合了現代與傳統的魅力。台北擁有世界知名的地標——台北101,它曾是全球最高的摩天大樓,並且是購物和觀光的熱門地點。此外,台北還有許多文化和歷史景點,如故宮博物院、龍山寺和中正紀念堂,吸引了大量國內外遊客。台北市內交通便捷,捷運系統發達,是探索這座都市的絕佳方式。這裡也是台灣美食的集中地,夜市文化如士林夜市、饒河街夜市更是不可錯過的體驗之一。
台中位於台灣中部,氣候溫暖,擁有台灣第三大城市的規模。它以文化氣息濃厚著稱,擁有豐富的藝術與文化活動,如國立台灣美術館、霧峰林家花園等。台中還是熱門的觀光景點之一,尤其以彩虹眷村和高美濕地最為著名。此外,台中市還以舒適的生活環境和悠閒的生活步調著稱,常被視為居住和發展的理想城市。台中的夜市文化也相當發達,逢甲夜市是其中最具代表性的夜市之一,吸引了無數美食愛好者前來品嚐台灣各地的美食
Answer:
**************************************************
** Response: **
assistant: YES
**************************************************
關聯性 Relevancy: 生成的回答與查詢及其上下文之間的相關性。這一評估確保生成的回答不僅正確,增加了考慮用戶查詢的內容。
from llama_index.core import VectorStoreIndex
from llama_index.llms.openai import OpenAI
from llama_index.core.evaluation import RelevancyEvaluator
# build index
...
# define evaluator
llm = OpenAI(model="gpt-4", temperature=0.0)
evaluator = RelevancyEvaluator(llm=llm)
# query index
query_engine = vector_index.as_query_engine()
response = query_engine.query(
"國立台灣美術館在哪裡?", similarity_top_k=2
)
eval_result = evaluator.evaluate_response(response=response)
print(str(eval_result.passing))
# OutPut[1]: True
【Prompt】
user: Your task is to evaluate if the response for the query is in line with the context information provided.
You have two options to answer. Either YES/ NO.
Answer - YES, if the response for the query is in line with context information otherwise NO.
Query and Response:
Question: 國立台灣美術館在哪裡?
Response: 台中
Context:
台北是台灣的首都,也是台灣政治、經濟、文化和交通的中心。這座城市充滿了活力與多元文化,結合了現代與傳統的魅力。台北擁有世界知名的地標——台北101,它曾是全球最高的摩天大樓,並且是購物和觀光的熱門地點。此外,台北還有許多文化和歷史景點,如故宮博物院、龍山寺和中正紀念堂,吸引了大量國內外遊客。台北市內交通便捷,捷運系統發達,是探索這座都市的絕佳方式。這裡也是台灣美食的集中地,夜市文化如士林夜市、饒河街夜市更是不可錯過的體驗之一。
台中位於台灣中部,氣候溫暖,擁有台灣第三大城市的規模。它以文化氣息濃厚著稱,擁有豐富的藝術與文化活動,如國立台灣美術館、霧峰林家花園等。台中還是熱門的觀光景點之一,尤其以彩虹眷村和高美濕地最為著名。此外,台中市還以舒適的生活環境和悠閒的生活步調著稱,常被視為居住和發展的理想城市。台中的夜市文化也相當發達,逢甲夜市是其中最具代表性的夜市之一,吸引了無數美食愛好者前來品嚐台灣各地的美食
Answer:
**************************************************
** Response: **
assistant: YES
**************************************************
LlamaIndex 提供了檢索評估指標,包含以下常見的六種指標:
命中率 (Hit Rate)
命中率是衡量系統在前 k 個檢索結果中正確答案出現的比例。這個指標有助於評估系統的初步檢索能力,越高的命中率表示系統在前幾個結果中能找到正確答案的能力越強。
平均倒數排名 (Mean Reciprocal Rank, MRR)
MRR 是用來評估系統返回結果的品質,特別是關注第一個相關結果的排名。 MRR越高表示系統能更快地找到相關答案。
精確率 (Precision)
精確率衡量的是所有被檢索出的文檔中,正確答案所佔的比例。高精確率意味著系統返回的結果大部分都是相關的,這對於使用者體驗非常重要。
召回率 (Recall)
召回率則是指在所有實際相關文檔中,被成功檢索出的比例。高召回率表示系統能夠找到大多數相關答案。
平均精度 (Average Precision, AP)
平均精度同時考慮精確率和召回率,通常用於評估排序結果。它是在不同閾值下計算精確率後取其平均值,特別適合多標籤分類問題。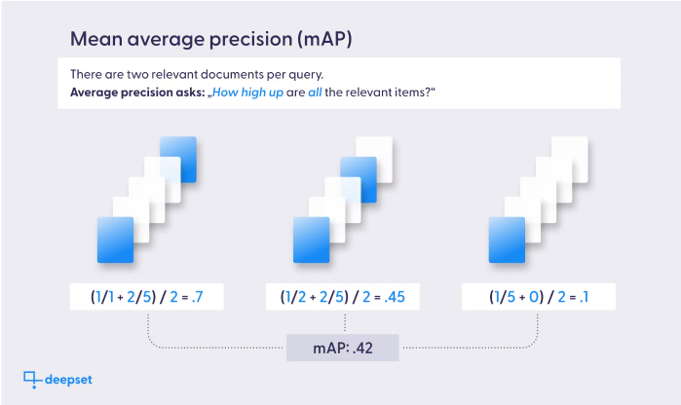
歸一化的折損累計增益 (Normalized Discounted Cumulative Gain, NDCG)
NDCG 是一種考慮到所有相關項目排名的指標,它根據排名賦予不同權重。數字為大代表檢索結果越相關且排序正確。
import os
os.environ["OPENAI_API_KEY"] = "YOUR-API_KEY"
from llama_index.core import Document, VectorStoreIndex
# Create document
text_chunks = [
"台北是台灣的首都,也是台灣政治、經濟、文化和交通的中心。這座城市充滿了活力與多元文化,結合了現代與傳統的魅力。台北擁有世界知名的地標——台北101,它曾是全球最高的摩天大樓,並且是購物和觀光的熱門地點。此外,台北還有許多文化和歷史景點,如故宮博物院、龍山寺和中正紀念堂,吸引了大量國內外遊客。台北市內交通便捷,捷運系統發達,是探索這座都市的絕佳方式。這裡也是台灣美食的集中地,夜市文化如士林夜市、饒河街夜市更是不可錯過的體驗之一。",
"新竹被譽為「風城」,因為當地的強風而得名。它位於台灣的西北部,距離台北約一小時車程。新竹是台灣高科技產業的重要基地,特別是以竹科(新竹科學園區)而聞名,是台灣的“矽谷”。新竹擁有良好的教育環境,著名的清華大學與交通大學皆位於此地。雖然新竹給人現代化的高科技城市印象,但它同時保留了豐富的歷史文化資產,如新竹城隍廟、新竹市東門城等。當地的風味小吃,如米粉和貢丸湯,也深受遊客喜愛,是品嚐道地台灣味的好去處。",
"台中位於台灣中部,氣候溫暖,擁有台灣第三大城市的規模。它以文化氣息濃厚著稱,擁有豐富的藝術與文化活動,如國立台灣美術館、霧峰林家花園等。台中還是熱門的觀光景點之一,尤其以彩虹眷村和高美濕地最為著名。此外,台中市還以舒適的生活環境和悠閒的生活步調著稱,常被視為居住和發展的理想城市。台中的夜市文化也相當發達,逢甲夜市是其中最具代表性的夜市之一,吸引了無數美食愛好者前來品嚐台灣各地的美食",
"台南是台灣最古老的城市,也是台灣的文化和歷史重鎮,擁有豐富的歷史遺跡和古蹟。作為台灣的發源地,台南保存了大量具有歷史價值的建築物,如赤崁樓、安平古堡和延平郡王祠。這座城市還以其宗教文化著名,每年都有多場盛大的廟會活動,如媽祖遶境、五廟祭典等,吸引大量信徒參與。台南同時也是美食天堂,台南小吃如擔仔麵、碗粿和牛肉湯聞名全台。台南擁有獨特的歷史氛圍與人文風情,讓每個造訪者都能感受到濃厚的古早味。",
"高雄是台灣的南部最重要的港口城市。高雄港是世界最繁忙的貨運港之一,帶動了當地的經濟發展。高雄市內的交通便捷,擁有輕軌和捷運系統,讓市民和遊客都能方便地遊覽這座城市。高雄的著名景點包括蓮池潭、打狗英國領事館、六合夜市等,是旅遊和購物的好地方。此外,旗津半島也是高雄知名的觀光勝地,以海灘、美食和古蹟著稱。高雄擁有豐富的自然景觀和現代化的都市建設,結合了傳統與現代的多元風貌。"
]
metadata_chunks = ['台北', '新竹', '台中', '台南', '高雄']
documents = []
for i, text in enumerate(text_chunks):
doc = Document(
text=text,
id_=f"doc_id_{i}",
metadata={"city": metadata_chunks[i]})
documents.append(doc)
# Indexing
index = VectorStoreIndex.from_documents(documents)
# Query
query = "國立台灣美術館在哪裡?"
# Create Retriever
retriever = index.as_retriever(similarity_top_k=3)
relevant_node = retriever.retrieve(query)
# Create Evaluator
from llama_index.core.evaluation import RetrieverEvaluator
metrics = ["hit_rate", "mrr", "precision", "recall", "ap", "ndcg"]
retriever_evaluator = RetrieverEvaluator.from_metric_names(
metrics, retriever=retriever
)
# 'e86cf47d-a3c7-4012-8a1a-2dd9bcc3ee15'代表正確檔案的 Node ids(Label的概念),系統會比對檢索結果和提供的 expected_ids 計算以上分數。
eval_result = retriever_evaluator.evaluate(
query=query, expected_ids=['e86cf47d-a3c7-4012-8a1a-2dd9bcc3ee15']
)
print(eval_result)
# OutPut[1]: Metrics: {'hit_rate': 1.0, 'mrr': 0.5, 'precision': 0.3333333333333333, 'recall': 1.0, 'ap': 0.5, 'ndcg': 0.2960819109658652}
LlamaIndex🦙 提供了強大的工具來評估生成模型的品質,無論是忠誠度、相關性評估等,都有助於改善生成結果的準確性。此外 LlamaIndex 透過多種檢索指標,為開發者提供了數據分析和優化檢索效果的方式。這些功能不僅提升了模型的性能,也使其在真實應用中更具實用性。通過結合生成與檢索評估,開發者可以在LLM性能上進行精細調整,確保更高品質的回應和用戶體驗。
時間過得非常快,經過這 15 天的介紹已經將 LlamaIndex 大致上的功能介紹完了,從 Hige-Level 到 Low-Level Function 學會這些內容你也能夠將 LlamaIndex 運用自如。


 iThome鐵人賽
iThome鐵人賽